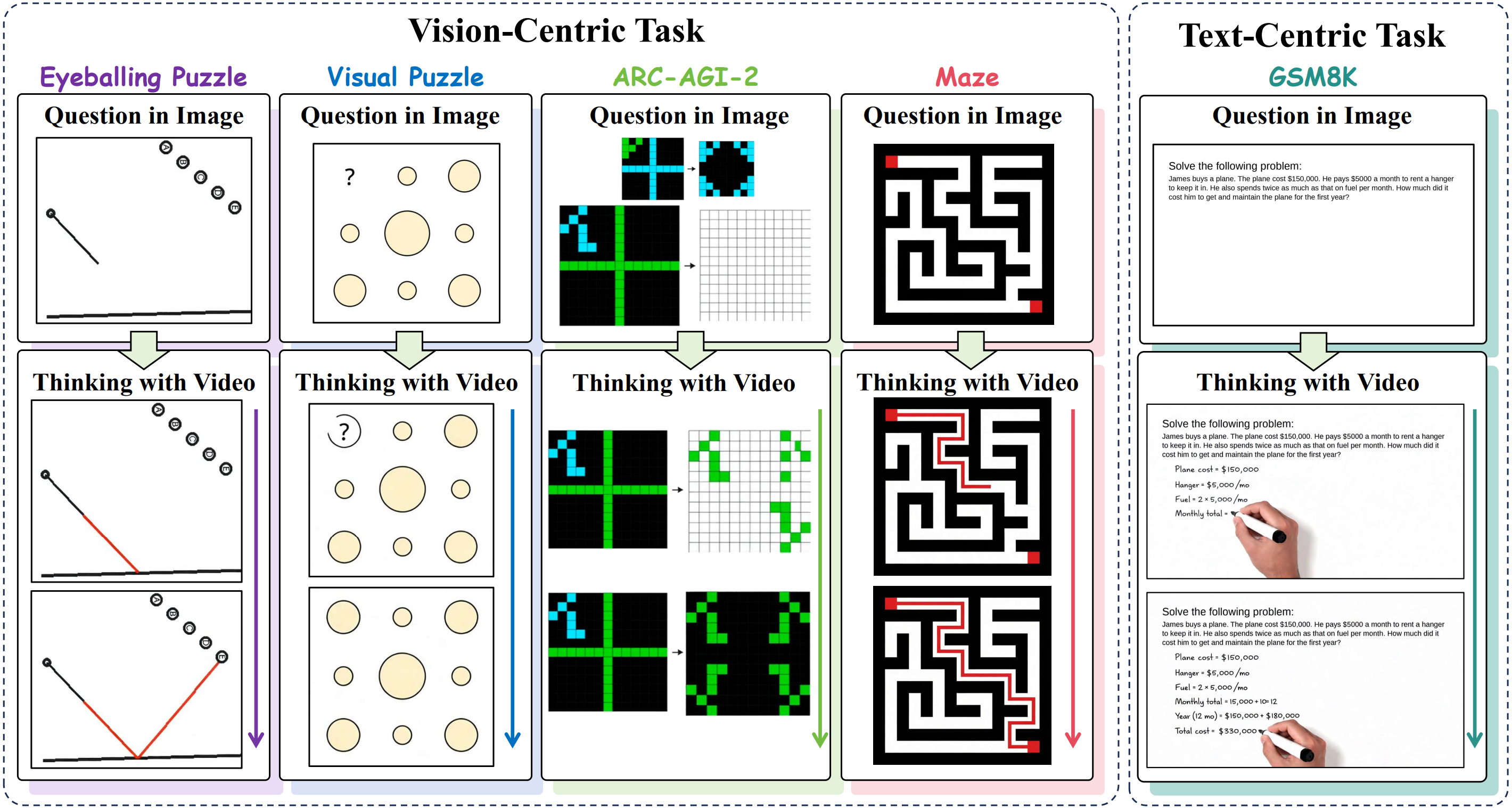
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
1Fudan University
2Shanghai Innovation Institute
3Central South University
4The Chinese University of Hong Kong
* Core contribution † Corresponding authors

TL;DR
We introduce "Thinking with Video", a new paradigm leveraging video generation for multimodal reasoning. Our VideoThinkBench shows that Sora-2 surpasses GPT5 by 10% on eyeballing puzzles and reaches 69% accuracy on MMMU.
GSM8K
Visual Puzzle
Ray Reflection
ARC-AGI-2
Maze
Abstract
"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU).
Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Puzzles. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 69.2% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2’s performance.
In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positioning "Thinking with Video" as a unified multimodal reasoning paradigm.
Leaderboard on VideoThinkBench (minitest)
Video Generation Models
Vision-Language Models
Note:
"Eyeballing Point/Line/Shape" refer to Point Tasks, Line Tasks and Shape Tasks in Eyeballing Puzzles. The results are Major Frame evaluation results.
"Visual Symmetry/Gradient/Compositionality" refer to the Symmetry Tasks, Gradient Tasks and Compositionality Tasks in Visual Puzzles.